The Theresa May Government is struggling with Brexit. Its members continue to use vacuous phrases and empty rhetoric in an attempt to disguise their lack of exit strategy.
“Brexit means Brexit” was one such, and was a strong indicator that her EU Exit vehicle was running on empty. (‘Scuse me mixing my own metaphors.)
The High Court’s simple rebuttal of the Government’s contention that it could use the Royal Prerogative to invoke Article 50 highlighted its paucity of understanding surrounding the process of leaving the EU.
“Not revealing its strategy” is defended by use of another mistaken analogy. The Government says it would be wrong to “reveal its hand”. This is an utterly false aphorism. We are not doing anything like playing a game of cards with the EU. We are not sat round a gambling table.
We are not negotiating a business deal either. Describing it as such is equally wrong. A business deal is between a supplier and a customer of goods or services.
Leaving the EU is not about getting the best deal between a seller and a buyer where you have to “sound each other out” before discussing the price and other terms. An International Trade Agreement is at a higher level than that and describes the terms (tariffs, taxes, regulations) nations or a group of nations want to have between them.
To do so requires both parties, AT THE OUTSET, to declare what they want as outcomes from those negotiations. The model the EU uses can be seen in the negotiations for TTIP with the USA or for CETA with Canada. These negotiations START with a table of things that has two columns – those that are not contended and those that are so. The process of working out how to resolve those that are contentious takes months and years. (7+ years for CETA)
And with our relationship with the EU we have to do TWO DISTINCT THINGS – we have to negotiate LEAVING and we then have to negotiate a NEW DEAL.
Article 50 only refers to the leaving. It gives us two years to negotiate how we separate ourselves from the 43 year relationship and all its entanglements. This, we should remember, has never been done before. There is no model to follow. The UK had only International Trade negotiators with which to embark on this mission.
And then, like the USA and Canada, we have to work on a NEW DEAL WITH THE EU.
The closest analogy is DIVORCE (leading to decree nisi, palimony payments etc) and then POST DIVORCE ARRANGEMENTS. (On friendly terms, of course. Right?)
But that isn’t something that’s ever been done, remember. And it’s further complicated by being a massively Polygamous marriage. One with two main wives and 25 other wifelets of varying importance, but any of whom could veto any of the arrangements…
Maybe Boris’s words will come back to haunt him, “Brexit is going to be a TITANIC success”. With him as a principal player, it’s not hard to imagine.
Pretty unbelievable, but true, is that (since Office 2003?) Microsoft Excel cannot properly handle Unicode UTF-8 Import and Export to look after your accented and other special characters used on your website. (Try exporting µ ≥ or ≤ or just a ° Degree sign!)
You can get Excel to import UTF-8 Menu > Data > From Text > CSV file > Import dialogue: [options] UTF-8
But it will screw up on your carriage return/line feeds, and the data will be (literally) all over the place. Duh!
The only option I have found that worked was to use LibreOffice Calc (and not ApacheOffice Calc, where IFERROR() doesn’t seem to work).
Using that for Unicode UTF-8 Imports and Exports worked absolutely fine, and your Website will look like it should…
I manage a client’s WordPress installation which delivers digital documents using Easy Digital Downloads as the primary plugin.
Recently they asked me to facilitate sharing documents bi-directionally with partners, distributors and subscribers.
This included adding a large document library of over 2,000 documents initially, and a small number later, incrementally.
Experimenting with EDD’s own Import routine demonstrated that it was (admittedly) “pretty useless”.
And our original design web design was flawed in that the original data import had been done by taking separate fields and merging them into an HTML table that populated the Description field. (There had been no requirement for data sharing in the original specification.)
So my plan was to move this data out, and then back into separate fields, enabling future data imports and exports in a “normal” way.
The first thing I did was to use the Advanced Custom Fields Plugin to extend the EDD posts with additional fields. This was pretty straightforward. Indeed, why the original developer and his “data guru” didn’t use this approach originally, is beyond me…
But how to get and populate these new ACF fields with the Data?
After a long wait for such, in Jan 2016, EDD 2.5 was released with a new, simple, and much more effective Data Export module. That meant I could get the Downloads data into a Spreadsheet to manipulate it. (But not using Excel, rather LibreOffice Calc – see Excel UTF-8 gotcha, here.)
Getting the right info out of the HTML Table data, required fairly complex formula: string searching, splitting and length deducing and also needing to first remove surplus HTML tags. (How it got up to three <strong> tags is also beyond me…)
For anyone interested, this is an example of how to get a formula to find variable length Data, in this case after the emboldened word “Form:” from the data table:
So I then had the right data, but how to get it back into the Downloads? My contracted “Data Programmer” had gone AWOL, so it was down to me.
Research kept me coming back to the Plugin WP All Import. And it supported both Custom Fields (in the paid Pro version) and ACF (with a paid Add-on). I tried the “test me” site, but it crashed as soon as I Activated the EDD plugin. <sigh> But it looked as though it should work. So I paid my $138 (Pro plus the ACF Add-on) on the basis of a Guaranteed Money Back, if it didn’t work.
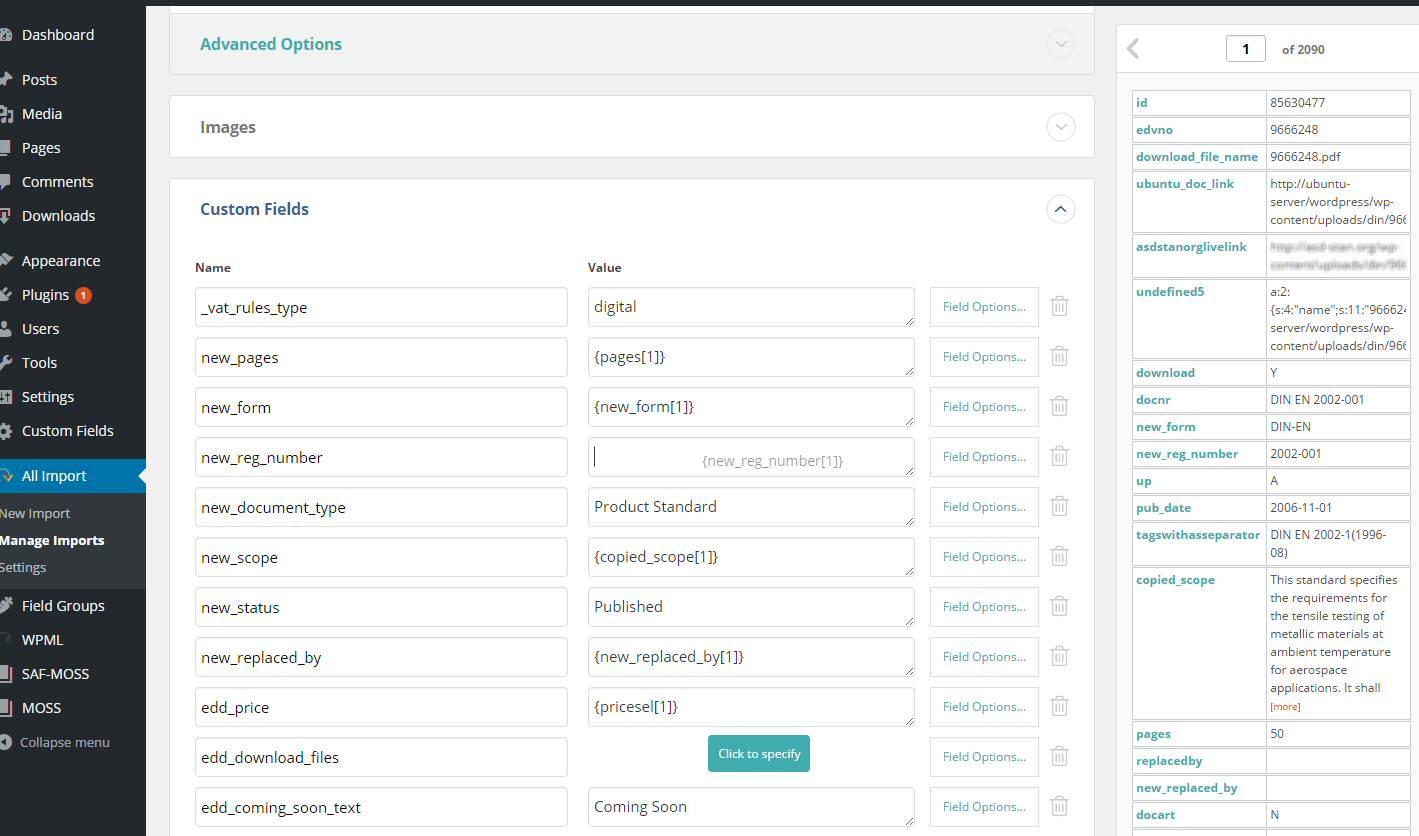
After a lot of experimenting on the staging server set up to do exactly that, I had worked out that adding data back into the ACF custom fields was more straightforward than I’d originally thought, and that I didn’t even need the ACF fields add-on (and I got my $38 refunded, without any problem). As the EDD data is all referenced by the Key field Post_ID, getting the separated data back into the new ACF fields in the right record was a drag and drop operation.
WP All Import Drag & Drop csv data into field
So that was the add data to my new ACFields sorted.
What about bringing a whole new data set in? I’d received (and cleaned, rectified missing accented characters etc.) my external data file.
And that was working as above except for one, but critically important part – the EDD Download files and Location.
The 1st thing was getting my files onto the Server – I wasn’t going to use the Media Library routine to load up 2,000 plus docs. But once they’re FTPd onto the server, they still need to be registered in the Library. EDD used to recommend the simple Plugin Add to Server to remedy this but that doesn’t (and according to its author, never will) handle large volumes of files.
Instead, I used a more sophisticated Plugin Media from FTP. This is pretty straightforward, even if it takes time to scan the /uploads directory tree. One thing to watch out for, is to uncheck the Organise into month and Year folders option in the Plugin’s settings – otherwise it will move your files (and they’ll be in the wrong place for the next step).
And that brings us to bringing in where EDD will look for its files. The field it uses is edd_download_files which WPAllImport shows you in Custom Fields . The problem arises because that value is an Array, because it can have multiple values (you can have more than one file per Download page), which itself contains a two part array – [file] and [name].
If you use WPAllImport to Auto-Detect, you’ll see it renders a “serialized” data value. Looking something like
Key 0 and Value a:2:{s:4:”name”;s:15:”myfile.pdf”;s:4:”file”;s:70:”http://ind-tech.com/wp-content/uploads/edd/myfile.pdf”;}
Where myfile.pdf is the first record in the edd_download_field table
Initially, I didn’t understand what that was. If I used it, each record was populated (so that was something) but each one had the same value of that first record. The WPAllImport log said
edd_download_field updated with `a:1:{i:0;a:2:{s:4:”name”;s:15:”myfile.pdf”;s:4:”file”;s:70:”http://ind-tech.com/wp-content/uploads/edd/myfile.pdf”;}}` for post `Post Name
I tried adding [file] and [name] as additional lines, and got various combinations of similar output, but nothing that would render an array within an array.
This issue arises, I found, because MySQL cannot store data in “real” arrays. (Wow!?) Instead it has to serialize and unserialize array data when storing and retrieving such an array. So the vales starting “a:2” are the serialized data.
As far as I could find, WPAllImport doesn’t give you an option to handle Arrays within Arrays. That means you have to create an array field value yourself, and import that.
This means you have to have create an intermediate spreadsheet: source_data.csv >> intermediate.ods >> import_for_edd.csv
And the value you have to create has to calculate for each record, a) the value of the file name, b) the value of the path+filename, and c) the number of characters in each of those. For my spreadsheet, this meant have a formula like this:
which produced the requisite output for each row: a:2:{s:4:”name”;s:15:”myfile1.pdf”;s:4:”file”;s:70:”http://ind-tech.com/wp-content/uploads/edd/myfile1.pdf”;}
a:2:{s:4:”name”;s:15:”myfile2.pdf”;s:4:”file”;s:70:”http://ind-tech.com/wp-content/uploads/edd/myfile2.pdf”;} and so on… and when the import was run it created the “unserializable” Value e.g: a:1:{i:0;a:2:{s:4:”name”;s:15:”myfile1.pdf”;s:4:”file”;s:70:”http://ind-tech.com/wp-content/uploads/edd/myfile1.pdf”;}} for each post (Download)
(It has to be quite complicated, as you need e.g. to have quotation marks (CHAR(34)) in the right places. In my spreadsheet , column C contained the myfile.pdf name and column D contained the path+filename.)
And that, after a lot of trial and working out pathname errors, worked! All files correctly locatable and downloadable – phew!
Hope that helps if you’re trying to do the same thing…